此篇基本上是译文,原文是 Victor Eijkhout 所著的《TeX by Topic》的第二章。译文项目参见:CTeX-org/tex-by-topic-cn。
转载请保留本段文字,尊重原作者和译者版权。
由于原著使用 GFDL,故而本文也被传染地同样使用 GFDL 许可,而不是本站默认的 BY-NC-SA 4.0 许可。
读取字符时,TeX 的输入处理器会为字符分配分类码。根据读取到字符的分类码,输入处理器会在三种内部状态之间切换。本章讨论 TeX 是如何读取字符的,以及字符的分类码是如何影响读取行为的。本章还将讨论空格及行尾的相关问题。
在本文的翻译中:行尾(line ends)是一行末尾及相关问题的统称,行终止符(end-of-line character)是 TeX 的输入处理器主动添加在输入行末尾的字符,行尾符是操作系统中用于标识一行结尾的字符,例如:回车符(carriage return)与换行符(line feed)。
概述
TeX 的输入处理器从文件或终端扫描输入行,而后将读取到的字符转换成记号。输入处理器可视作一简单的有限状态自动机,其具有三种内部状态;根据输入处理器所处内部状态的不同,其扫描行为有所不同。本章将分别从内部状态和控制内部状态转换的分类码两个角度来考察该自动机。
初始化处理
TeX 逐行处理来自文件的输入(也可能是来自终端的输入,但实际甚少使用,故不再提及)。此处首先讨论在 TeX 语境下,到底什么是「输入行」。
不同计算机系统对输入行的具体定义有所不同。最常见的方式是用回车符(carriage return)紧跟换行符(line feed)作为行尾符,有些系统单用换行符作为行尾符,一些有定长存储(块存储)的系统则根本不使用行尾符。因此,TeX 在结束一行输入时有自己特定的处理方式。
- 从输入文件读取一行输入行(不包含可能的行尾符)。
- 移除行尾空格(这是针对块存储系统设计的,同时避免了因行为空格不可见而导致的混乱)。
- 将编码为
\endlinechar 的行终止符(默认是 ASCII 编码为 13 的 <return>)添加在行尾。若 \endlinechar 的值为负或大于 255(在低于 TeX 3 的版本中则是 127),则输入处理器不会添加任何行终止符;在输入行尾添加注释字符也有相同的作用。
不同计算机在字符编码方面也存在差异(最常见的是 ASCII 和 EBCDIC)。因此,TeX 有必要将从文件读入的字符转换为其内部编码。这些编码仅在 TeX 内适用,因此 TeX 在任何操作系统上的行为都保持一致。
分类码
256 个字符编码(0–255)中的每一个都关联了一个不尽相同的分类码。TeX 的分类码共有 16 个,从 0 开始编号至 15。在扫描输入流的过程中,TeX 会生成由字符编码和分类码组成的字符编码-分类码配对(character-code–category-code pairs);而后,基于这些配对,输入处理器将它们处理成字符记号、控制序列记号和参数记号。这些记号随后被传给 TeX 的展开处理器和执行处理器。
字符记号是简单的字符编码-分类码配对,它们会直接被传给展开处理器。控制序列记号则由转义字符引导,后接一个或多个字符组成。关于控制序列记号和参数记号的介绍详见下文。
以下就这些分类做简单说明,详细的阐述则散布在本章其他位置及后续章节当中。
0,转义字符;用于标记控制序列的开始。IniTeX 默认使用反斜线 \ 作为转义字符(ASCII 码为 92)。1,分组开始符;TeX 遇到此类字符时,会进入新的一层分组。在 plain TeX 中,默认的分组开始符是左花括号 {。2,分组结束符;TeX 遇到此类字符时,会关闭并从当前分组中退出。在 plain TeX 中,默认的分组开始符是左花括号 }。3,数学切换符;此类字符是数学公式的左右定界符。在 plain TeX 中,默认的数学切换符是美元符号 $。4,制表符;在 \halign(\valign)制作的表格中,作为列(行)间分隔符。在 plain TeX 中,默认的制表符是与符号 &。5,行终止符;TeX 用来表达输入行结束的字符。IniTeX 将回车符 <return>(ASCII 编码为 13)作为默认的行终止符。这就是为什么 IniTeX 中,\endlinechar 的值是 13(详见前文)。6,参数符;用于表示宏的参数。在 plain TeX 中,默认的参数符是井号 #。7,上标符;在数学模式中表示上标;也可用于在输入文件中表示无法直接输入的字符(详见后文)。在 plain TeX 中,默认的上标符即是 ^。8,下标符;在数学模式中表示下标。在 plain TeX 中,默认的下标符是下划线 _。9,被忽略字符;此类字符将被 TeX 自输入流中清除,因此不会影响后续处理。在 plain TeX 中,默认将空字符 <null>(ASCII 编码为 0)设置为被忽略字符。10,空格符;TeX 对待空格符的方式较为特殊。IniTeX 将空格 <space>(ASCII 编码为 32)作为默认的空格符。11,字母;IniTeX 默认只将 a ... z 和 A ... Z 分为此类。在宏包中,某些「隐秘」字符(例如 @)会被暂时分为此类。12,其他字符;IniTeX 将所有未归于其他类的字符归于此类。因此,数字和标点都属于此类。13,活动字符;活动字符相当于一个无需转义字符前导的 TeX 控制序列。在 plain TeX 中,只有带子 ~ 是活动字符,表示不可断行的空格。14,注释符;TeX 遇见注释符后,会将从注释符开始到输入行尾的所有内容视作注释而忽略。在 IniTeX 中,默认的注释符是百分号 %。15,无效字符;该分类包含了不应在 TeX 中出现的字符。IniTeX 将退格字符(ASCII 编码为 127)<delete> 归于此类。
用户可使用
\catcode 命令修改字符编码到分类码的映射:
\catcode<number><equals><number>
该语句中,第一个参数可用如下方式给出:
`<character> 或者 `\<character>
两种写法都表示该字符的字符编码。
plain TeX 格式使用
\chardef 命令将
\active 定义为:
\chardef\active=13
因此上述语句可写成这样:
\catcode`\{=\active
LaTeX 格式定义了如下两个控制序列,用于开启或关闭「隐秘字符」
@(详见下文):
\def\makeatletter{\catcode`@=11 }
\def\makeatother{\catcode`@=12 }
使用
\catcode 命令查询字符编码对应的分类码,可得到一个数字:
\count255=\catcode`\{
在例中,
{ 的分类码被保存在第 255 号
\count 寄存器中。
下列语句可用于检测两个记号的分类码是否相等:
\ifcat<token1><token2>
无论
\ifcat 后有什么,TeX 都会将其展开,直至发现两个不可展开的记号;而后,TeX 将比较这两个记号的分类码。控制序列的分类码被视为 16;因此,所有控制序列的分类码都是相等的,而与所有字符记号的分类码都不相等。
从字符到记号
从文件或用户终端扫描输入行后,TeX 的输入处理器会将其中的字符转换为记号。记号共有三种。
- 字符记号:字符记号会被打上相应的分类码,而后直接传给 TeX 的后续处理器。
- 控制序列记号:严格来说,控制序列记号分为两种。其一是控制词 —— 分类码为 0 的字符后紧跟一串字母(分类码是 11)。其二是控制字符 —— 转义字符后紧跟单个非字母字符(分类码不是 11)。在无需区分控制词和控制字符的场合,它们统称为控制序列。由转义字符与一个空格字符
␣ 构成的控制序列,称为控制空格。
- 参数记号:由一个参数符 —— 分类码为 6,默认为
# —— 和一个紧跟着的1..9 中的数字构成。参数记号只能在宏的上下文中出现。连续两个参数符(字符编码不一定相同)会被替换为单个字符记号。该字符记号的分类码是 6(参数符),字符编码则与上述连续两个参数符中后者的字符编码相同。最常见的情形是 ## 会被替换为 #,其分类码为 6。
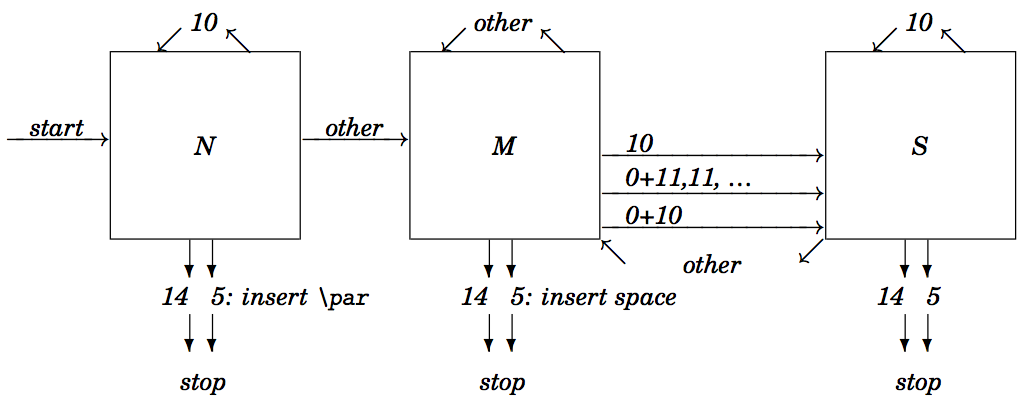
输入处理器是有限状态自动机
TeX 的输入处理器有三种
内部状态,可看做是一个有限状态自动机。这也就是说,在任意瞬间,TeX 的输入处理器都处于并且只能处于三种状态的一种;并且在状态切换完成后,TeX 的输入处理器对先前的状态没有任何记忆。
状态 N:新行
当且仅当遇到新的输入行时,TeX 会进入状态 N。在该状态下,TeX 遇到空格记号(分类码为 10 的字符)即会将之忽略;遇到行终止符则会将之替换为
\par 记号;遇到其它记号,则会切换到状态 M。
状态 S:忽略空格
在状态 M 下遇到空格记号,或在任意状态下遇到控制词或控制空格之后(注意其他控制字符不在此列),TeX 会进入状态 S。在该状态下,TeX 遇到空格记号或行终止符都会忽略。
状态 M:行内
显然,状态 M 是输入处理器最常见的状态,它表示「处理到输入行的中间」(middle of line)。当输入处理器遇到分类码为 1–4、6–8 以及 11–13 的字符或者控制字符(不包括控制空格)之后,就会进入该状态。在该状态下,TeX 会将行终止符替换为空格记号。
访问整个字符集
大体上,TeX 的输入处理器可以认为是一个有限状态自动机,但严格来说它并不是。输入处理器在扫描输入行期间,为了让用户能够输入一些特殊字符,而设计了这样的机制:两个相同的上标符(分类码为 7)以及一个字符编码小于 128 的字符(暂称原字符)组成的三元组会被替换为一个新的字符。该字符的编码位于 0 – 127 之间,并且与原字符的编码相差 64。
这种机制可用于访问字体中难以输入的字符。例如 ASCII 中的控制符号
<return>(ASCII 编码为 13)和
<delete>(ASCII 编码为 127)可分别使用
^^M 和
^^? 进行访问。当然,由于
^^? 是无效字符(分类码是 15),故而在访问前需要先修改其分类码。
在 TeX3 中,该机制被扩展为可以访问 256 个字符:四元组
^^xy 会被替换为一个编码在 0 – 255 之间的字符;其中
x 和
y 是小写十六进制数字
0–
9,
a–
f,而
xy 正是该字符编码的十六进制表示。这一扩展也给先前的机制带来了一些限制:例如
^^7a 会被输入处理器替换为
z,而不是
wa。
译注:w 和 7 的 ASCII 编码之差为 64。由于 7a 可被理解为是一个十六进制数,所以 TeX 贪婪地将四元组看做一个整体替换为 z。
这种机制一方面使得 TeX 的输入处理器在某种意义上比真正的有限状态自动机更为强大,另一方面还不会影响其余的扫描过程。因此,在概念上,可以简单地假装认为这种对
^^ 引导的三元组或四元组的替换是提前进行的。不过,在实践中这样做是不可能的。这是因为,在处理输入行的过程中,用户可能将其他字符分类为第 7 类,从而影响后续处理。
译注:也就是说,如果没有其他字符被分类为第 7 类,则这个假设在实践中也是可行的。
内部状态切换
现在我们来讨论特定分类码的字符对 TeX 输入处理器内部状态的影响。
0:转义字符
遇到
转义字符后,TeX 开始构建控制序列记号。取决于转义字符后面的字符之分类码,所得的控制序列记号有三种类型。
- 若转义字符后的字符之分类码为 11,即字母,则 TeX 将转义字符和之后连续的分类码为 11 的字符构建成一个控制词,而后进入状态 S。
- 若转义字符后的字符之分类码为 10,即空格,则 TeX 将它们构建成名为控制空格的控制字符,而后进入状态 S。
- 若转义字符后的字符之分类码不是 10 也不是 11,那么 TeX 将它们构建成控制字符,而后进入状态 M。
控制序列名字的所有字符必须在同一输入行之中;控制序列的名字不能跨行,即使当前行以注释符结尾或者没有行终止符(通过将
\endlinechar 设置为 0 – 255 之外的值)。
1–4, 7–8, 11–13:非空字符
分类为 1–4、7–8 及 11–13 的字符会被转换为字符记号,而后 TeX 进入状态 M。
5:行终止符
遇到行终止符时,TeX 的行为取决于输入处理器当前的状态。但不论处于何种状态,TeX 会忽略当前行,而后进入状态 N 并开始处理下一行。
- 处于状态 N,即当前行在此前只有空格,TeX 将插入
\par 记号;
- 处于状态 M,TeX 将插入一个空格记号;
- 处于状态 S,TeX 将不插入任何记号。
此处「行终止符」指得是分类码为 5 的字符。因此,它的字符编码不一定是
\endlinechar,也不一定非得出现在行尾。详见后文。
6:参数符
在宏定义的上下文中,参数符 —— 通常为
# —— 可跟
1..9 中的数字或另一个参数符。前者产生参数记号,而后者产生单个参数字符记号待后续处理。在这两种情形中,TeX 都会进入状态 M。
单独出现的参数符也被用于阵列的模板行。
7:上标符
TeX 对上标符的处理和大多数非空字符一样,仅在上述替换机制中有所不同:连续两个字符编码相同的上标符及其后字符组成的三元组或四元组会按规则被替换为其它字符。
9:被忽略符
分类码为 9 的字符会被忽略,且不会影响 TeX 的状态。
10:空格符
在状态 N 和状态 S 中,不论字符编码是多少,空格记号—— 分类码为 10 的记号 —— 都会被忽略;同时 TeX 的状态保持不变。在状态 M 中,TeX 会向正在构建的记号序列中插入
␣(类别码为 10),并进入状态 S。这意味着空格记号的字符编码可能与输入字符的编码不同。
译注:不论输入的是哪一个分类码为 10 的字符,输入处理器都会将其替换为字符编码为 32 的 ASCII 空格。
14:注释符
TeX 遇到注释符后,会忽略当前行之后包括注释符本身在内的所有内容。特别地,TeX 会忽略行终止符。因此,哪怕是在状态 M 下,TeX 也不会插入额外的空格记号。
15:无效字符
TeX 遇到无效字符时会报错,而 TeX 自身会停留在之前的状态。不过,在控制字符的上下文中,无效字符是合法的。因此,
\^^? 不会触发报错。
分类码中的字母与其他字符
大部分编程语言的标识符可由字母与数字构成(还可能包含其他诸如下划线之类的字符)。但是,在 TeX 中,控制序列的名字只能由第 11 类字符(即字母)组成。而通常,数字和标点的分类码是 12,即其他字符。
此外,TeX 可以产生一些由第 12 类字符组成的字符串,哪怕其中的字符原本并非都是第 12 类字符。
此类字符串可由
\string、
\number、
\romannumeral、
\jobname、
\fontname、
\meaning 以及
\the 等命令生成。若这些命令产生的字符串包含空格字符(ASCII 编码为 32),则在输出的字符串中,该字符的分类码为 10。
在极个别情况下,控制序列的展开中可能会包含十六进制数字;因此,除了通常表示字母的
A(11) –
F(11) 之外,TeX 中还有表示十六进制数字的
A(12) –
F(12)。
举例来说,
\string\end
得到四个字符记号
\(12)e(12)n(12)d(12)
注意,此处输出中有转义字符
\(12) 的原因是宏
\escapechar 的值是反斜线的字符编码。而若将
\escapechar 的值改为其它字符的编码,则
\string 将输出另一个字符。
通过一些特殊技巧,空格也可以出现在控制序列的名字当中:
\csname a b\endcsname
是一个控制序列记号,其名称由三个字符组成,并且其中之一是空格符。将这个控制序列转化为字符串
\expandafter\string\csname a b\endcsname
可得
\(12)a(12)␣(10)b(12)。
举个更加实用的例子。假设有一系列输入文件:
file1.tex、
file2.tex,而我们希望写一个宏来输出当前正在处理的文件的序号。第一种解法是:
\newcount\filenumber
\def\getfilenumber file#1.{\filenumber=#1 }
\expandafter\getfilenumber\jobname.
宏定义中,参数文本中的
file 会吸走
\jobname 中的
file 部分,从而留下文件编号作为宏的参数。
但这段代码有些小问题。
\jobname 输出的
file 四个字符,其分类码为 12。但在
\getfilenumber 的定义中,
file 四个字符的分类码是 11。为此,需要对上述代码进行以下修正:
{\escapechar=-1
\expandafter\gdef\expandafter\getfilenumber
\string\file#1.{\filenumber=#1 }
}
此处,
\escapechar=-1 让
\string 忽略反斜线;因此
\string\file 的结果会是
f(12)i(12)l(12)e(12) 四个字符。为了在宏定义是得到分类码为 12 的四个字符,我们使用
\expandafter 命令让
\string\file 在宏定义之前先行展开;而由于
\escapechar 的设定被放在分组内部,所以我们需要使用
\gdef 进行宏定义。
\par 记号
在遇到
空行之后,也就是在状态 N 遇到行终止符(分类码为 5)之后,TeX 会向输入中插入一个
\par 记号。具体来说,由于 TeX 遇到任何非空格字符,都会从状态 N 转移走,因此空行只能包含分类码为 10 的字符。特别地,空行不能以注释符结尾。因此,若输入文件中因格式美观需要保留空行,则可以在该行中放一个注释符。这算是 TeX 这一特性的常见用法。
两个连续的空行产生两个连续的
\par 记号,而实际上它们等同于一个
\par 记号:在遇见第一个
\par 记号之后,TeX 会进入竖直模式,而在竖直模式中,
\par 只是充当 TeX 页面构建器,起到清空段落形状参数的作用。
TeX 于非受限水平模式(unrestricted horizontal mode)遇到竖直命令(
<vertical command>)时,也会向输入插入一个
\par 记号。当该
\par 被读取和展开后,上述竖直命令会被重新处理。
\end 命令也会向输入插入
\par 记号,而后结束 TeX 的运行。
值得注意的是,遇到空行时 TeX 通常的行为(结束当前自然段)完全取决于
\par 记号的默认定义。重定义
\par 后,空行和竖直命令的行为可能就完全两样了;因此,我们可以借此实现一些特别的效果。在这种情况下,为了使用正常的
\par 的功能,plain TeX 提供了其同义词
\endgraf。
除非宏被声明为
\long 的,不然
\par 记号不能出现在宏的参数当中。对于非
\long 声明的宏,若其参数中包含
\par 记号,则 TeX 会给出「runaway argument」的报错。不过,使用
\let 定义的与
\par 同义的控制序列(例如
\endgraf)是允许出现在这些宏的参数之中的。
空格
这一节讨论输入处理器中有关
空格字符和
空格记号的一些内容。有关文本排版中的空格,留待后续章节讨论。
被忽略的空格
在上述有关输入处理器内部状态的讨论中,我们不难发现,有些空格在输入处理器中就被抛弃了,因此永远不会被输出:输入行开头的空格以及在让 TeX 进入状态 S 的字符之后的空格。
另一方面,行终止符尽管不在输入中(而是由 TeX 添加的),但能产生可输出的空格。除此之外,还有第三种空格:它们可以通过输入处理器,甚至干脆由输入处理器产生,但也不会被输出。那便是非强制空格(
<optional spaces>)。在 TeX 的语法中,很多地方都会出现此类空格。
非强制空格
TeX 语法中有所谓
非强制空格与
单个非强制空格的概念:
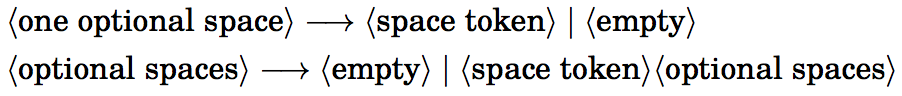
通常单个非强制空格(
<one optional space>)允许出现在数字和粘连说明之后;而非强制空格(
<optional spaces>)允许出现在数字或粘连中任意允许出现空格的地方(比如负号与数字之间,又比如
plus 和
1fil 之间)。此外,根据
<equals> 的定义,非强制空格允许出现在
= 之前。
以下是有关非强制空格的一些例子:
被忽略和被保留的空格
TeX 会忽略控制词之后的空格。不过这不是因为控制词之后的空格是非强制空格,而是因为 TeX 在遇到控制词之后会进入状态 S,从而忽略空格。类似地,控制词之后的行终止符也会被忽略。
数字由单个非强制空格界定,但是
a\count0=3 b
的输出是 “ab”。这是因为 TeX 在第一个空格记号之后会进入状态 S,从而第二个空格会被 TeX 的输入处理器忽略,永远不会变成空格记号。
当 TeX 处于新行状态 N 时,空格也会被忽略。另一方面,当 TeX 处于竖直模式工作时,空格记号(也就是在一开始未被忽略的空格)会被忽略。例如说,下例第一个盒子之后由行终止符生成的空格记号会被忽略。
\par
\hbox{a}
\hbox{b}
plain TeX 和 LaTeX 格式都定义了名为
\obeyspaces 的宏。该宏能使每个空格都是有意义的:在一个空格之后,连续的空格会被保留。两种格式中,
\obeyspaces 的基本形式是一致的。
\catcode`\ =13 \def {\space}
不过,对于
\space 的定义,两种格式有所区别。在 plain TeX 中,
\space 的定义如下
\def\space{ }
在 LaTeX 中,同名的宏则定义为
\def\space{\leavevmode{} }
在
\obeylines 的上下文中,比较容易看出这两种定义的区别。使用
\obeylines 后,每个行终止符都会被转换成一个
\par命令。因此 TeX 开始处理每一行时,都处于竖直模式。在 plain TeX 中,活动空格被展开为空格记号,因此在垂直模式中会被忽略。但在 LaTeX 中,首先会离开竖直模式并进入水平模式,因此每个空格就都是有意义的了。
空格被忽略的其他情形
还有三种情形下,TeX 会忽略空格记号:
- 在寻找未被花括号定界的宏参数时,TeX 会忽略所有空格记号,而将第一个非空记号(或分组)作为参数。
- 在数学模式中,所有的空格记号会被忽略。
- 在阵列制表符之后,空格记号会被忽略。
空格记号:<space token>
在 TeX 中,空格总是表现得与众不同。举例来说,
\string 会将所有字符的分类码设置为 12,唯独空格的分类码是 10 。此外,如前文所述,在状态 M 中,TeX 的输入处理器会将所有分类码为 10 的字符转换为真正的空格:字符编码会被设置为 32。于是,任何分类码为 10 的字符记号称为
空格记号(
<space token>)。字符编码不是 32 的空格记号称为
滑稽空格。
举例来说,将字符
Q 的分类码设置为空格字符之后,如下定义
\catcode`Q=10 \def\q{aQb}
可得
\show\q
macro:-> a b
这是因为输入处理器改变了宏定义中滑稽空格的字符编码。
字符编码不为 32 的空格记号可以用
\uppercase 等命令生成。不过,「由于字符编码不同的空格记号的行为是一致的,所以纠缠于这类细节是没有意义的」。详见 TeXbook 第 377 页。
控制空格
控制空格命令
\␣ 给出一个与
\spacefactor 等于 1000 时空格记号宽度一样的空格。控制空格不能被当做是空格记号,也不能理解为会展开成一个空格记号的宏(例如 plain TeX 中的
\space)。举例来说,TeX 会忽略所有输入行开头的空格,但是控制空格是一个水平命令(
<horizontal command>),故而 TeX 在遇到它之后会从竖直模式切换到水平模式(并插入一个缩进盒子)。
可见空格:␣
在 Computer Modern 的打字机字体中,字符编码为 32 的字符是显式空格符号 “
␣“。不过,简单地使用
\tt 命令是无法将其打印出来的。这是因为空格在输入处理器中有特别的处理。
使空格字符
␣ 显形的一种方法是将空格字符的分类码设置为 12:
\catcode`\ =12
此时,TeX 会将空格字符作为编码为 32 的字符排版出来。此外,连续的空格不会被忽略。这是因为状态 S 只是在遇到分类码为 10 的字符后才会进入。类似地,控制序列之后的空格也会因分类码的改变而显形。
有关行尾的更多知识
TeX 从输入文件中获取文本行,但不包括输入行中的行尾符。因此,TeX 的行为不依赖操作系统以及
行尾符究竟是什么(CR-LF、LF 抑或是在块存储系统里根本就不存在行尾符)。而后,TeX 会移除输入行末尾的空格。这样处理是有历史原因的:TeX 必须能够适应 IBM 大型计算机的块存储模式有关。对于由计算机的不同而造成的有关行尾符的问题。
此后,字符编码为
\endlinechar 的行终止符会被追加在文本行的末尾;除非
\endlinechar 中保存的数值为负数或大于 255。注意,改行终止符的分类码不一定非得是 5。
保持各行
有时候会期望会希望输入文本中的行尾符能与排版输出的行尾一一对应。下面的代码可以可以解决这一问题:
\catcode`\^^M=13 %
\def^^M{\par}%
这里,
\endlinechar 成为活动符,其含义变为
\par。上述代码中的注释符用于阻止 TeX 看到代码末尾的行终止符,以防它将其作为活动字符而展开。
需要注意的是,在将上述代码嵌入宏的展开文本中需要特别小心。例如说下列代码会让 TeX 误解:
\def\obeylines{\catcode`\^^M=13 \def^^M{\par}}
具体来说,TeX 将丢弃第二个
^^M 之后的所有字符。这是因为,在宏展开的过程中,
\catcode 命令尚未执行,因而此时
^^M分类码为 5,而非 13。也就是说,这一行实际上变成了:
\def\obeylines{\catcode`\^^M=13 \def
要修正上述问题,需要为
^^M 营造一个可作为活动字符使用的环境:
{\catcode`\^^M=13 %
\gdef\obeylines{\catcode`\^^M=13 \def^^M{\par}}%
}
这样解决了上面提到的问题,但仍有缺陷。这是因为,该
\obeylines 仍然不能保留输入文本中的空行——连续两个
\par 记号会被当成是一个。为此,我们需要对上述定义稍作改进:
\def^^M{\par\leavevmode}
这样,输入文本中的每一行都会开启一个新段落,空行则开启一个空段落。
改变 \endlinechar
某些情况下,你会希望改变
\endlinechar 的值或者
^^M 的分类码,以达成一些特殊效果。例如说,可以用行终止符作为宏的参数的定界符。
在这些常识中,通常会有一些陷阱。我们来看以下写法:
{\catcode`\^^M=12 \endlinechar=`\^^J \catcode`\^^J=5
...
... }
这段代码的输出不符合预期:由于第一行和最后一行的行终止符,TeX 将输出字符码为 13(
^^M)和 10(
^^J)的字符。
在第一行和最后一行末尾加上注释符可以解决此问题,但还有另一种方法是将第一行拆成下面两行:
{\endlinechar=`\^^J \catcode`\^^J=5
\catcode`\^^M=12
当然,在多数情况下没必要将行终止符替换为另一个字符;设置
\endlinechar=-1
就等同于各行都以注释符结尾。
行终止符的更多注记
TeX 对所有字符一视同仁,包括追加到输入行末尾的行终止符。考虑到它特别的分类码,通常大家都不会注意行终止符。但是有一些方法可以特别地处理行终止符。
举例来说,假定
\endlinechar 保持默认值为 13,那么,把 “
M“。因为它是编码为 13+64 的 ASCII 字符。
再举例来说,如果
\^^M 有定义,此时可称为「控制换行」。则在输入行中用反斜线结尾将执行此控制换行命令。例如,在 plain TeX 中定义
\def\^^M{\ }
将使得控制换行与控制空格等价。
输入处理器的更多知识
输入处理器作为独立过程
TeX 处理器的各个阶段都是同时运行的,但是在概念上它们常被视为依次独立运行,前者的输出是后者的输入。关于空格的小戏法很好地展现了这一点。
考虑以下宏定义:
\def\DoAssign{\count42=800}
及其调用:
\DoAssign 0
作为构建记号的部分,TeX 的输入处理器在扫描此次调用时,会忽略控制序列之后和零之前的所有空格。因此,此次调用的展开为:
\count42=8000
不要认为:「
\DoAssign 首先被读入,而后展开,而后空格作为分隔符分割了 800,于是 800 被赋值给计数器,并打印出数字零。」不过,需要注意的是,如果数字零出现在下一行,情况就不一样了。
再举一个让非强制空格出现在忽略空格阶段之后的例子:
\def\c.{\relax}
a\c. b
会被展开为:
a\relax b
其输出是:
a b
这是因为,「输入处理器忽略控制序列
\relax 之后的空格」这一现象仅出现在该行被首次读取之时,而非在其被展开之时。
另一方面,这个例子:
\def\c.{\ignorespaces}
a\c. b
则会被展开为:
a\ignorespaces␣b
执行
\ignorespaces 时会删除所有接续其后的连续空格记号。因此,输出是:
ab
在上述两个例子中,
\c 之后的西文句号均为定界符,用于保护控制序列之后的空格不被输入处理器吃掉。
输入处理器不作为独立过程
将 TeX 的记号化的过程视作独立过程是一个便利的做法,但有时这种做法会引起困惑。
例如
\catcode`\^^M=13{}
将行终止符设为活动字符;因此,该行自身的行终止符将报错:「未定义的控制序列(undefined control sequence)」。这表明,执行行内的命令有时会影响对同一行的扫描过程。
另一方面,下面例子则不会报错:
\catcode`\^^M=13
这是因为,在 TeX 扫描数字 13 时就读入了行终止符,此时,分类码的赋值过程尚未执行;而此时,行终止符被转换成了非强制空格,作为数字的定界符。
输入处理器的递归调用
前文中,将参数符和数字替换为参数记号的过程被描述得与将字母捆绑成控制序列记号类似。但实际情况要复杂得多。TeX 的记号扫描机制不仅在扫描文件输入时起作用,在扫描记号列表输入时同样会起作用:例如在处理宏定义时。前文提到的内部状态变化的机制,仅仅适用于前一种情况。
在两种情况下,输入处理器对参数符的处理方式都是相同的。否则 TeX 便无法处理下面这样的宏定义:
\def\a{\def\b{\def\c####1{####1}}}
@ 约定
读过 plain TeX 或是 LaTeX 格式的源码就会发现其中有很多包含符号
@ 的控制序列。这种包含
@ 的控制序列不能被普通用户直接使用。
格式文件的起始处附近有命令
\catcode`@=11
它将
@ 的分类从「其他字符」变为「字母」,从而可以用于组成控制序列。而在格式文件的末尾处附近有命令
\catcode`@=12
它将
@ 的分类恢复为其他字符。
那么,为什么用户不能直接调用带有
@ 字符的控制序列,却能调用定义中包含此类控制序列的宏呢?原因在于,在宏定义时,带有
@ 的控制序列已被 TeX 内部处理过了,此后,这些控制序列就变成了记号而不是字符串了。在宏展开的过程中,TeX 只需要操作记号,因此,彼时记号内字符的分类码就不影响宏展开的过程了。
选自:
https://liam0205.me/2018/05/05/TeX-by-Topic-Category-Codes-and-Internal-States/

 通常单个非强制空格(
通常单个非强制空格(


发表评论 取消回复